Draft: Quantized Export to ONNX: Recipe for Transforming an Aidge Model into an ONNX-Quantized Friendly Model
Context
Aidge's and ONNX's quantization have different requirements and representations making it difficult to export directly a quantized aidge model into a quantized ONNX one.
The main focus of this merge request to add a Recipe that can be called on a quantized Aidge model to transform it into an exportable model. This will be done by regrouping the quantization operators in aidge into QuantizeLinear metaoperators, creation of corresponding DequantizeLinear metaoperators and if specified by the user also QlinearConv.
More Explainations on how and why will be present below. This merge request is directly related to aidge_onnx#42 (moved)
Modified files
-
ONNXRecipes.cppandONNXRecipes.hpp, Main function of the merge request, emplacement of the recipe to transform the quantized aidge model; -
PTQMetaOps.cpp, In Quantizer metaop creation, Producers were added with the corresponding min and max values to prevent dangling inputs; -
pybind_ONNXRecipes.cpp,pybind_ONNXRecipes.cpp, recipe pybind; -
freezeProducers.pyand__init__.py, secondary python function to freeze(turn constant) the weights and biases of convolutions and FC, made to simplify the usage of constant folding;
Detailed major modifications
Aidge and ONNX quantizations
To understand better why this recipe is needed it is important to see the different representations between Aidge's quantized model and a ONNX's quantized model.
Aidge quatization:
- Input directly into the convolution
- Mul and optionally Round node between the weights/biases producers and the convolutions inputs
- "Quantizer" meta operator in the convolution output. Quantizer is a metaop composed of Mul, optional Round and Clip
Onnx quantization:
has two modes QOP or QDQ the two having different representations but identical functionality.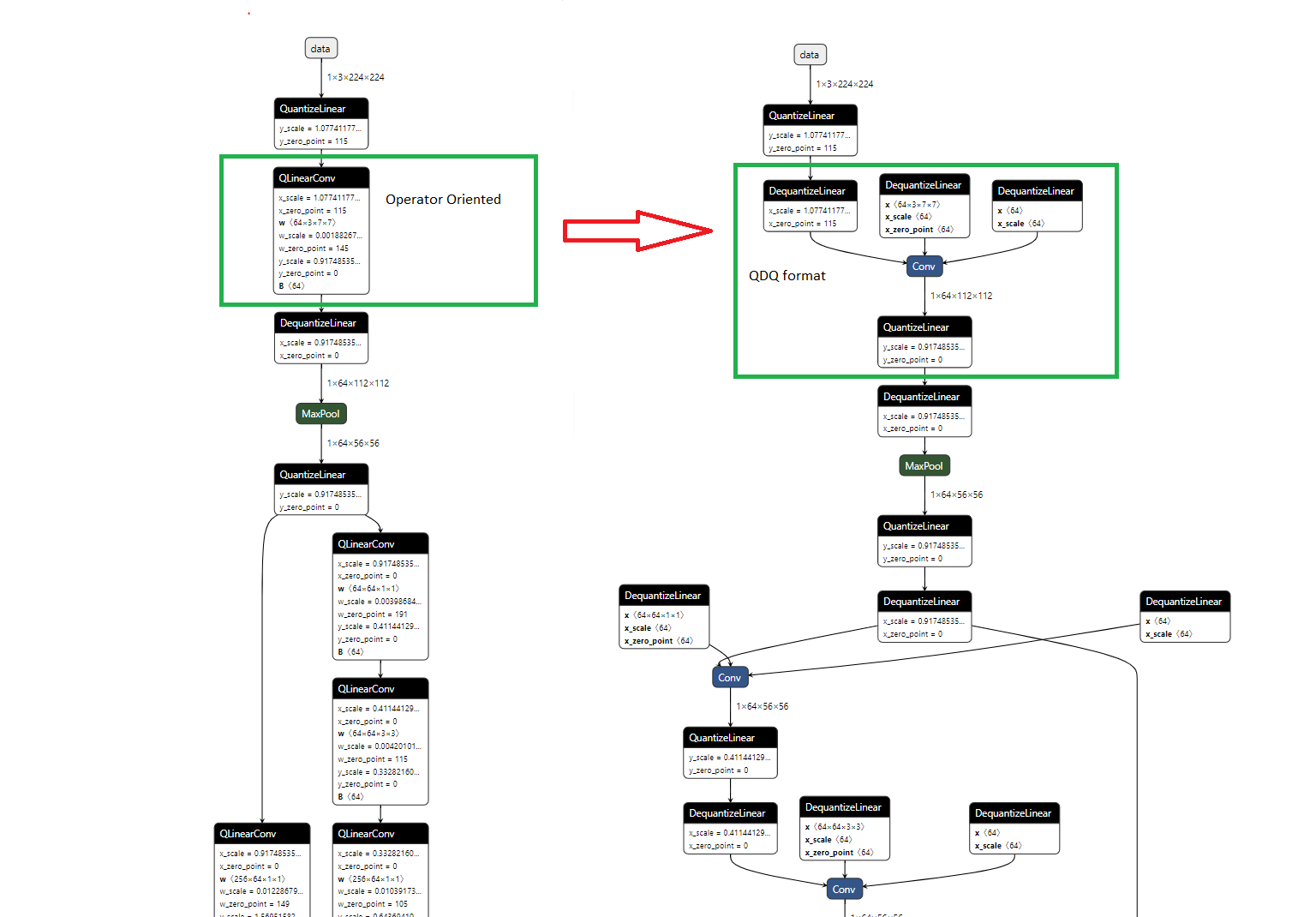 see: https://onnxruntime.ai/docs/performance/model-optimizations/quantization.html#onnx-quantization-representation-format
see: https://onnxruntime.ai/docs/performance/model-optimizations/quantization.html#onnx-quantization-representation-format
QDQ is based of QuantizeDequantize operations, if a lone convolution is quantized using this representation the result would be the following:
- Addition of QuantizeLinear operator at the input of the model
- Quantization of bias and weight that are then placed in a new initializers replacing the old values
- Addition of DequantizeLinear operators on all inputs of the convolution (Input, weight, bias)
- QuantizeLinear operator on the output of the convolution
- Dequantizelinear on the output of the graph
These modifications create a graph with a series of Quantize-Dequantize operators giving it it's name.
QOP is based on the "Quantized operators" in the subject of this mr I will focus on QlinearConv. A Quantized model using QOP would result in the following:
- Addition of QuantizeLinear operator at the input of the model
- Quantization of bias and weight that are then placed in a new initializers replacing the old values
- Replacement of the convolution node by a Qlinearconv node
- Dequantizelinear on the output of the graph
The series of QDQ surrounding the conv are now replaced by Q->qlinearconv->DQ, but as said before, Qlinearconv makes the same operation as Q->DQ->Conv->Q->DQ, making it equivalent to QDQ.
if this graph was to be used as it is, the operations performed in the convolution would still be in float despite it's quantized nature. But ONNX Runtime has a series of graph optimization options and run the model as intended. It is important to keep in mind that this is only a representation and it does not necessarily reflect what an inference would look like.
key differences:
- Quantization is performed differently: mul->round or mul->round->clip in aidge meanwhile onnx uses quantizelinear which is composed of div->round->add->saturate(clip equivalent) QuantizeLinear doc
- Dequantize operations are not performed on Aidge
- Qlinearconv Bias quantization imposes it's scaling factor to be biasSF = weighSF * inputSF, see qlinear_doc
- no quantization operator on graph input or dequantization operator on graph output in Aidge
- QlinearConv and DequantizeLinear (arguably QuantizeLinear, not the same operations) operators do not exist on Aidge
- Zero point does not exist on Aidge
Recipe operations
These two methods of quantization result in some pretty key differences making the export difficult. That is why this merge request adds a recipe that modifies a quantized aidge graph to be able to export it without imposing heavy modifications on aidge's onnx export functions.
This recipe will take a quantized aidge model and add/edit the following:
- Quantization operator on input and dequantization operator on output of the graph: initial quantization operator will have it's scaling factor set to 1. The purpose is to just have the initial QuantizeLinear present althought no operation is performed
- Mul->Rounds will be transformed into QuantizeLinear metaops, making them mul->round->add->cast and mul->round->add->cast->clip respectivelly (https://github.com/onnx/onnx/blob/main/onnx/backend/test/case/node/quantizelinear.py)
- DequantizeLinear metaops will be added to the convolutions inputs with the corresponding Scaling factor of the previous quantize operator, DequantizeLinear metaop is composed of Cast->Sub->Mul (order of operations of DQ onnx tests https://github.com/onnx/onnx/blob/main/onnx/backend/test/case/node/dequantizelinear.py)
- "fold" the quantization of the bias and the weights: replace the producer->quantizelinear with it's corresponding value
- If QOP: create a QlinearConv metaoperator from DQ->Conv->Q and the other dequantize linear operators on its weights and bias
- if QOP: modify bias and bias scaling value so it respects the formula weightSF * inputSF = biasSF. Meaning newbiasSF = weightSF * inputSF and newbias = (biasSF * bias) / newBiasSF
- if QOP: especify bias producer dtype to int32 QlinearConv B dtype
Some other small modifications may be performed
This graph modifications are made to accomodate to ONNX's Quantized model representation so it can be run as any other quantized model on ONNX runtime
TODO
-
resolve bug regarding a QuantizeLinear Cast datatype (expected uint8, has float) -
imposed folding of the bias values as of DQ and QLinearConv dtypes requirements -
more testing on the cascading values of Q-DQ pairs -
set backend dynamically -
add asserts to improve the robustness of the function -
add Cast node on QuantizeLinear's Add second input (zeropoint) to support Float addition -
consider possibility of other dtypes and its compatibility aidge-onnx
Cleaning
-
remove debug artifacts: Log::info, graphview->save, commented code -
better comments and verbose