[onnx] ONNX export quantified models
This issue track the progress of the export in ONNX of quantized models.
This issue is more generic than: #42 (moved) and try to adress all the problems related to exporting a quantized ONNX model.
About ONNX quantized models
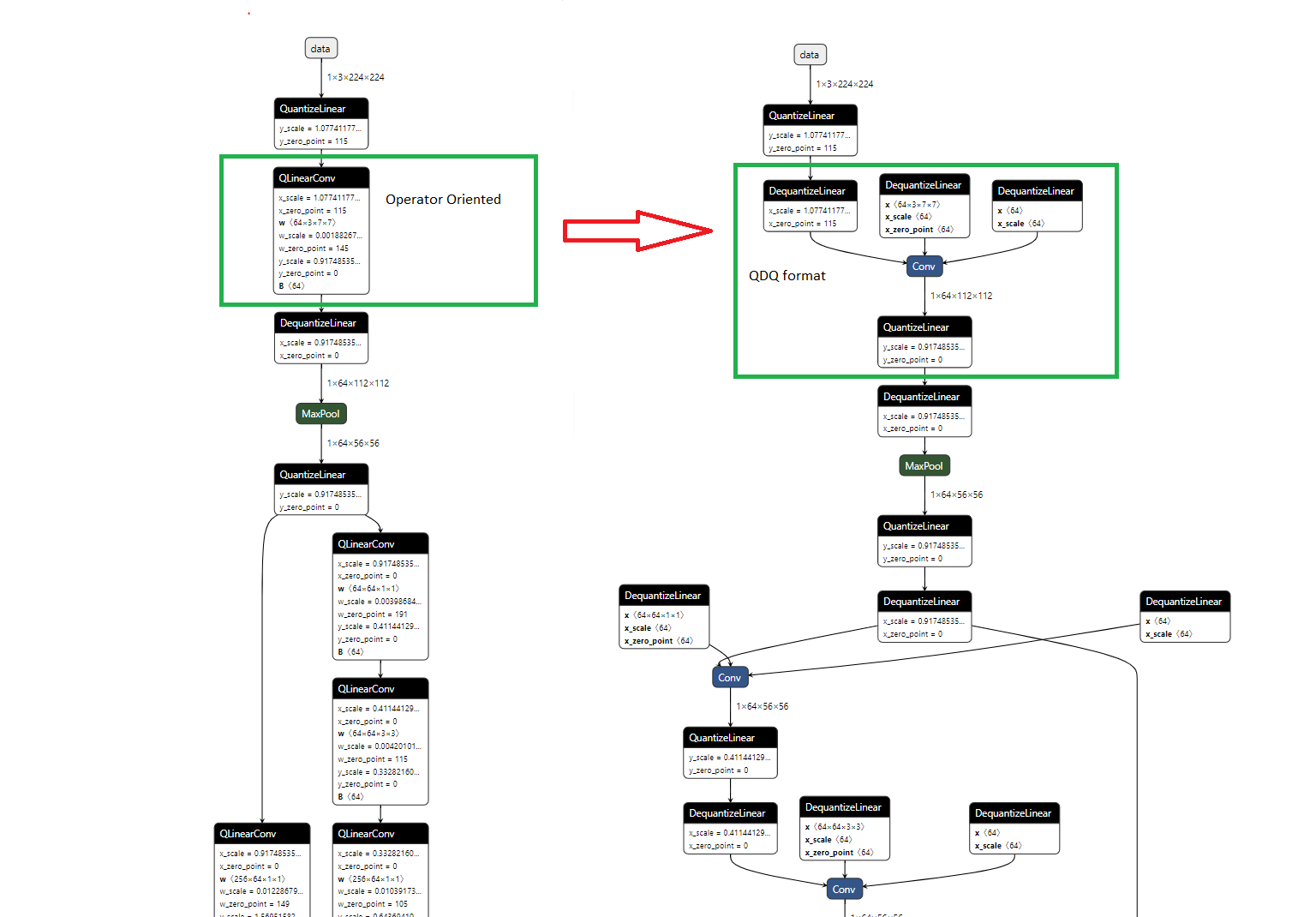
ONNX standard distinguish two formats of quantized models:
- QOperator: Equivalent a fully quantize Operator (Take int8 as input and return int8 as output)
- QDQ: Use Full precision operator and insert quantize and dequantize nodes.
The difference between the two standards are illustred bellow:
ONNX introduces the following operators:
- QuantizeLinear: Quantize tensor, equivalent to a Mul, Round, Clip, Cast.
- DequantizeLinear: Dequantize tensor
- QLinearConv: A fully int8 (or int4) convolution
-
QGemm: A fully int8 (or int4) Gemm (Note: this operator is from the extended opset
com.microsoftand is not standard, however this is the operator used by onnxrt quantization method)
Going from fake quantize to true quantize
After PTQ method, the model is "fake quantized". This means the used data type is fp32 but the dynamic is the one you are quantizing to (for example int8).
In order to pass to a true quantize graph, we need to add cast nodes.
This is important in order to export to ONNX as we need to introduce the cast operations in the graph.
Ideally, the full export to ONNX worfklow would look like:

With the true quantize representation we will be able to directly match the QGemm and directly export to it.
However, going to the true quantize graph is not trivial and cannot be done directly from the fake quantized graph as we need information on the expected type to cast to. Indeed, if we quantize the network with 8bits for weights and 4bits for activation how can we know that the output of the quantize node need to be cast to int4?
In order to pass from the "fake" to "true" quantize graph I propose a function that will do so, this function will use either:
- an object
QuantizationScheme. TheQuantizationSchemeis a map that for each nodes specify the weight data type and the activation data type as well as information on if the quantization is per tensor or per activation. The QuantizationScheme will be an output of the PTQ method. - attributes stored in each nodes during the PTQ. The idea being to create a namespace Quantization and store the informations in each nodes.
Handling non quantized operator
In ONNX not every operator are quantized.
flowchart TD
Input -->|INT8| QGemm -->|INT8| MaxpoolHere this graph is not valid because maxpool does not support int8. Even if it would be possible to support it in the Aidge representation!
This require an extra step during the ONNX export where we need to add DequantizeLayer.
To do so, I propose during the export to use ONNX schemas definition that allow to check if an operator support int8 or not.
See the following snippet that highlight the ONNX API:
import onnx
# Get the schema of the operator
op_type = "Add" # Replace with the desired operator
opset_version = 18 # Use the appropriate opset version
schema = onnx.defs.get_schema(op_type, opset_version)
# Print the allowed types for each input
for i, input_param in enumerate(schema.inputs):
print(f"Input {i} ({input_param.name}): {input_param.typeStr}")
# Display the type constraints
for type_constraint in schema.type_constraints:
print(f"Type Variable: {type_constraint.type_param_str}")
print("Allowed Types:")
for allowed_type in type_constraint.allowed_type_strs:
print(f" - {allowed_type}")TODO:
-
Pass from fake quantized to true quantize graph. -
Add set_to_qdq method -
Add set to qop (fuse Operators to QGemm or QLinearConv) -
Add export support for quantize operators: -
QLinearConv -
QGemm -
DequantizeLinear -
QuantizeLinear
-
-
Add import support for quantize operators: -
QLinearConv -
QGemm -
DequantizeLinear -
QuantizeLinear
-